一、Stream(流) 基础介绍
Stream 中文翻译“流”。
其一个重要的的特点就是为按需处理,即“读一点数据处理一点数据”。
日常生活中最常见的“流”就是音视频流了。
当然,作为编程人员我们知道,除了音视频流,还存在字节流、比特流等。
流连续且没有头尾,没有绝对位置,它不是一个容器,只是一个抽象概念,可以理解为是对程序与外界交换数据的一种抽象。
在数据处理上,流处理是最常见也是最实用的处理的方式。
比如 Unix 操作系统中的管道运算符。
1 | cat logfile.txt | grep 2021/05/20 |
如上命令的作用就是查看日志文件 logfile.txt 中包含 ‘2021/05/20’ 字符串的日志记录。
管道符 ‘|’ 让左边 cat 命令查看的数据,像流水一样流向右边,作为 grep 命令的输入,而 grep 命令就是一个过滤网,过滤掉不需要的数据。
仅仅留下 ‘2021/05/20’ 相关的日志。
类似于上面的例子,我们日常编程中也用到了很多类似文件操作,最常见的就是对于磁盘文件的读写了。
市面上比较流行的编程语言都实现了自己的流,Nodejs 就是其中之一。
作为前端开发,日常生活中接触最多的语言就是 javascript,而早期的 Javascript 作为网页脚本语言,本身是没有实现流的。
直到后来 Nodejs 的出现。
Nodejs 作为后端编程语言,它提供了很多 Javascript 没有的能力,集成在它的核心模块里面。
Nodejs 的 Stream 模块就是 Nodejs 语言对于流的实现。
二、Nodejs 核心模块 Stream 在生产环境中的运用
平时使用 Nodejs 做一些小工具开发或者使用 Koa/express 开发后端应用的时候,很少甚至可以说没有直接用到 Stream 模块。
我们很难在某个 Nodejs 应用中找到直接使用 stream 模块的代码,比如
1 | const stream = require('stream') |
但是我们一定很熟悉这样的代码。
1 | // 例1 |
如上代码中的 http 和 fs 模块让我们可以用个位数的代码行数实现一个 http 服务器。
能够让我们如此便利编写服务器应用,其背后的模块就是 stream。
三、Stream 的作用
实现 http 服务器的有很多,返回文件的方式也各种各样,比如不同意 例1 中的实现方式
我们采用如下方式来实现。
将原来通过 fs.createReadStream 的方式读取文件改为 通过 fs.readFile 方法直接读取。
1 | // 例2 |
这段代码和前面例子的区别在于,读取文件的方式。
前面是创建文件流,然后将文件流通过 pipe 方法传送给 res。
后面的例子值直接读取整个文件,然后将文件通过 end 方法返回。
看上去没什么问题,两中方式都能实现,我们实际写一个 index.html 文件来运行也不会出现什么问题。
那么哪种方式更好呢?
1 | 答案是:第一种,使用文件流的形式。 |
为什么呢?
我做了一个测试,我创建了一个特别大的 html 文件特别大,1G+。
然后第一个例子能正常跑,第二个例子直接报错了。
1 | url is http://localhost:3000/ |
报错的原因字符串过长,超过了0x1fffffe8 (536870888 Byte === 512 MB)。
原来,当我们使用 fs.readfile 或者 fs.readfileSync 的时候是先将文件存储在内存中,一次性读取
一次性读完之后再进行下一步,如果文件过大,就会触发最大字符串长度限制,导致出错。
那么,为什么第一个例子中不会报错呢?
答案就是 Stream,对于这种情况,采用流处理的方式是不会报错,哪怕文件再大都没问题。
为什么使用流就不会报错呢?
如上图所示,直接读取文件和通过 stream 读取就是类似于上图
一个是一次性搬运,另一个是将数据分为一小块一小块的进行传输。
很显然,后者更轻松。
四、Stream 模块在 Nodejs 中的位置
Stream 模块本身主要用于开发者创建新类型的流实例,对于以消费流对象为主的开发者,极少需要直接使用 Stream 模块。
它类似于一个基类,其它模块都是继承此基类实现的子类。
http 请求的 req/res 以及 fs 模块的 createReadStream 等都是基于 stream 的实现。
如下图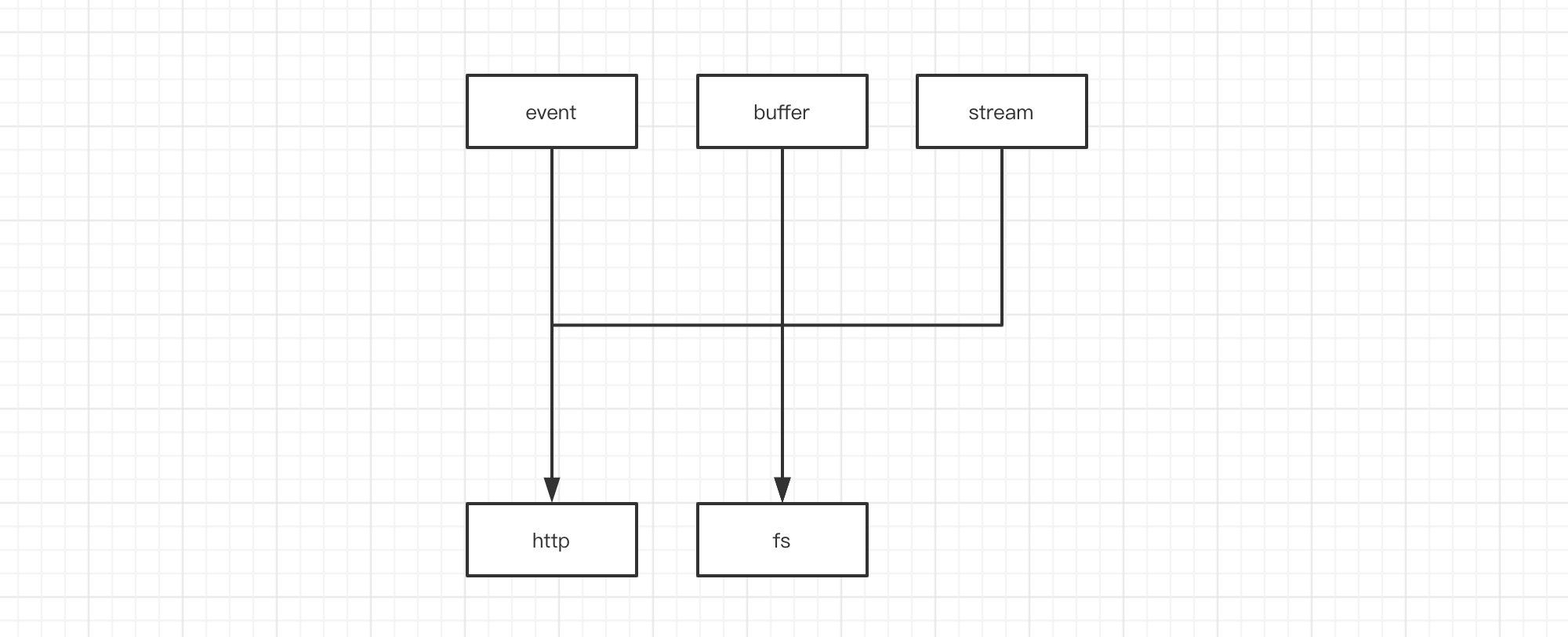
http 依赖于 event、stream、buffer
fs 依赖于 event 和 stream、buffer
上面只是一个简化版的依赖关系图,其实际比这个复杂的多,比如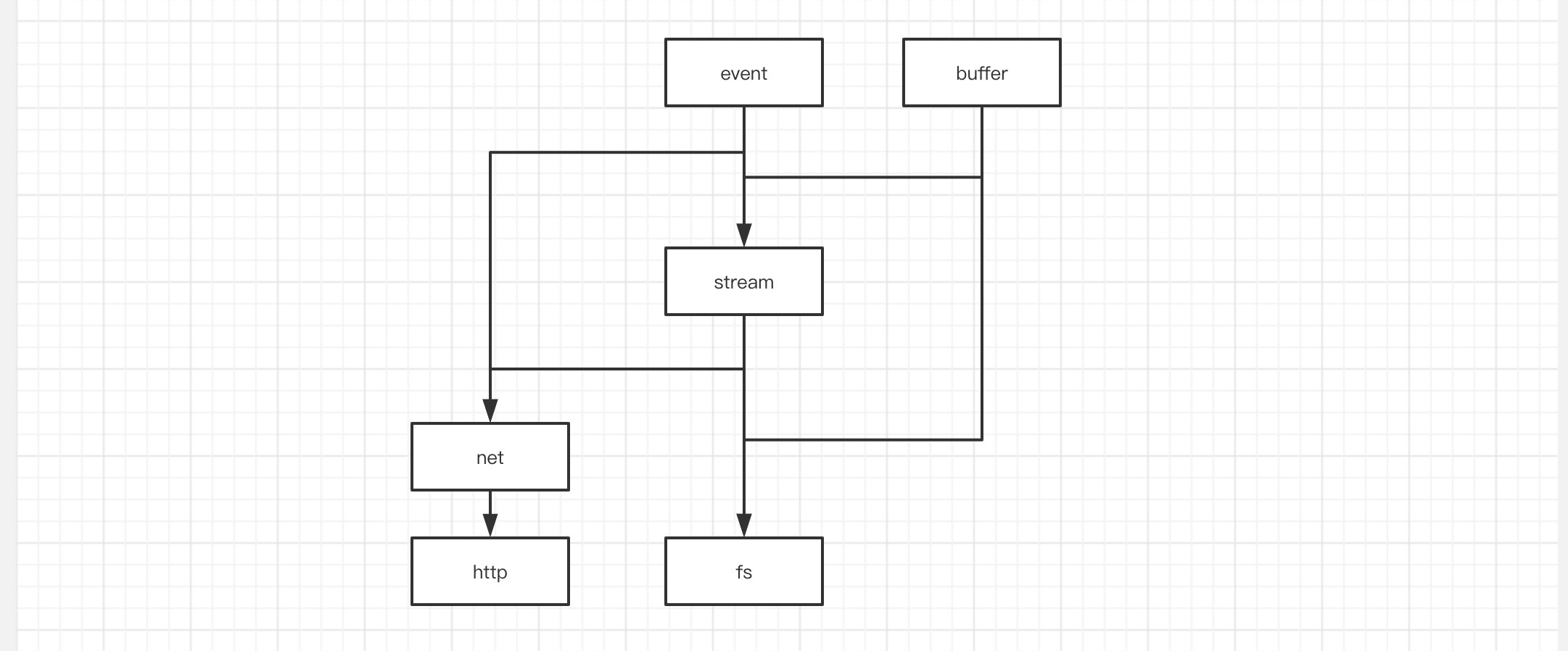
当然,这几个模块作为nodejs 的基础能力,与其它模块以及互相之间依赖关系其只会更复杂。
有兴趣可以去 Nodejs 源码逐个分析了解,本文的重心还是在于介绍 Stream。
五、探索 fs.createReadStream 的实现
从 Nodejs 官方文档可知,fs.createReadStream 是基于 Stream 实现的。
1 | // node/lib/fs.js |
createReadStream 返回一个 ReadStream 的实例
可以看出,其核心实现还是在 internal/fs/streams.js 中
1 | // node/internal/fs/streams.js |
此文件导出类 ReadStream
但是该类最终是在核心模块stream中的 Readable 类中实现的。
fs.createReadStream 其实质上就是对于核心模块stream.Readable的一个继承实现。
没办法,要想搞清楚,还得继续探索。
从 nodejs 源码中可以找到这个 stream.Readable 类所在的文件 stream.js
1 | // node/lib/stream.js |
可以看出,stream.js 中 Stream 类分别实现了 readable、writable、duplex、transform四个方法
这也是官网以及网上很多资料所说的, Stream 中四大类流的方法。
1 | Writable - 可写入数据的流,可以通过管道写入、但不能通过管道读取的流 |
很明显,他们的实现还在其引入的文件中单独实现的,包括最原始的 Stream 类。
最原始的 Stream 类是基于 legacy.js 文件中的 Stream 类创建的。
好吧,继续找到 legacy.js 文件。
1 | // node/lib/internal/streams/legacy.js |
代码很长,但是这里并未对其进行精简,因为这就是实现流 pipe 处理的核心逻辑。
虽然代码多,但是其逻辑并不复杂,很容易就可以看出,这里就是 Stream 类的源头。
1 | Stream 类在 legacy.js 中创建 |
同时也可以看出
1 | 当 dest.write(chunk) === false 的时候 on data 执行 pause 暂停 |
source && dest
1 | pipe 方法除了事件监听,可以看到两个字段,分别是 source 和 dest |
关于 writeable 流
搞清楚了流的源头,接下来继续探索一下 readable 流。
从上面的源码不难看出,Stream.Readable 方法来自于文件 internal/streams/readable
1 | // internal/streams/readable |
如上就是 readable 文件提供的操作流的方法。
需要注意的是,其中_read()方法是一个抽象方法,这里直接抛出一个错误,这就是意味着如果要执行_read 方法,使用者必须自己实现。
push 方法将数据推入 readable 流中。
read 方法用来读取数据流。
_read 是 read 的底层实现,重写了 _read 方法,每次调用 read 的时候会触发_read.
六、流的工作过程
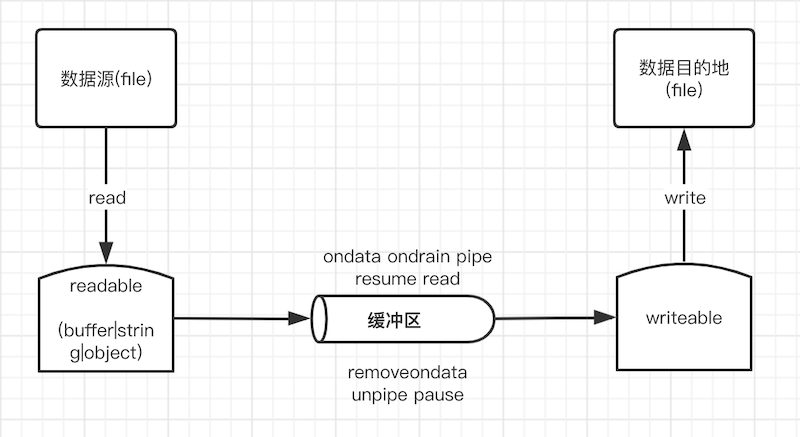
数据源 ——> 管道 ——> 缓冲区 ——> 目的地
1.readable 从数据源 file 读取数据
1 | 1) 创建的可读流对象可是二进制模式(buffer|string) 或者 普通对象模式 |
2.以下方式将 paused 变为 flowing(流动)状态,触发数据开始流动
1 | 1) 通过 on('data', ...) 事件触发 readableStream 的数据的流动 |
3.以下方式可以将 flowing 变为 paused
1 | 1) 当调用方式为 pipe() 时,先移除 data 的监听事件,然后调用 stream.unpipe() 方法清除所有管道,流状态将变为 paused |
4.流数据的消费
1 | 1) 流创建完成会触发 onreadable 事件,此时流已经准备好。 |
read()方法会从内部缓冲区中拉取并返回若干数据,没有更多可用数据时,会返回null。
使用read()方法读取数据,如果传入了 size 参数,会返回指定字节的数据,当指定的size字节不可用时,则返回 null。
不指定 size 参数,会返回内部缓冲区中的所有数据。
read() 方法仅应在暂停模式时被调用,在流动模式中,该方法会被自动调用直到内部缓冲区被清空。
七、关于积压或背压(Backpressure)
背压指在异步场景下,被观察者发送事件速度远快于观察者处理的速度,从而导致下游的 buffer 溢出,这种现象叫作背压。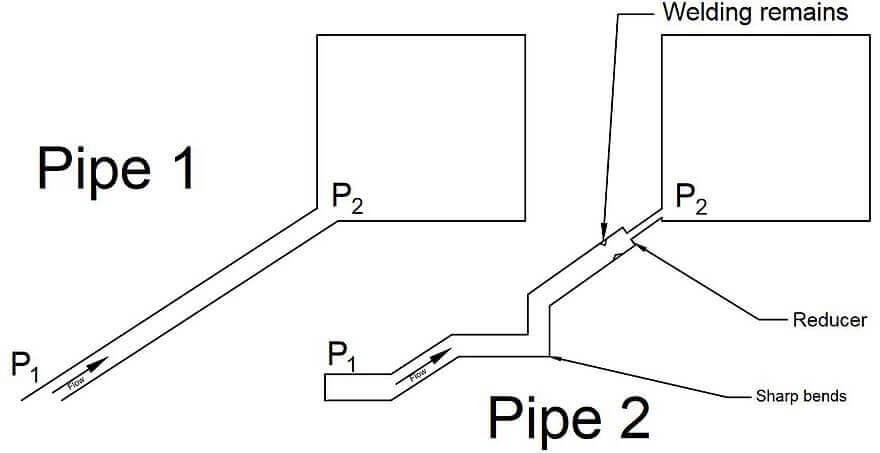
比如上图,管道入口处一样大,入口数据也一样,但是中间或者出口因为各种因素被阻塞或者减小了口径,导致流动受阻,形成背压。
在流的系统中,当 Readable 传输给 Writable 的速度远大于它接受和处理的速度的时候,会导致未能被处理的数据越来越大,占用更多内存。
之后更多的数据不得不保存在内存中直到整个流程全部处理完毕,形成恶性循环,最终导致内存溢出。
buffer、highWaterMark 与背压问题的解决方法
缓冲器(buffer)是流的读写过程中的一个临时存放点,是一个独立于 V8 堆内存之外的内存空间。
利用缓冲器能够将少量、多次的数据进行批量的在磁盘中读写;也能够将大块文件分批少量的进行搬运。
highWaterMark是一个可选参数,缓冲器中缓冲数据的大小取决于 highWaterMark 的值,它是一个阈值,默认 16kb (16384字节,对于对象模型流而言是 16)。
当缓冲器中数据达到 highWaterMark 的值时,会暂停从底层资源读取数据(readable._read),直到当前缓冲器中数据被消费完。
stream API的一个核心目标(特别是stream.pipe()方法)是把缓存的数据控制在可接受范围内。
八、如何实现自己的 Stream
那么它是如何实现的呢?
通过查阅 ReadStream.prototype._read 源码可知,其最最核心的原力就是重写了_read()方法。
1 | // 精简版本 |
toRead是n参数,表示一次读取的数据大小this.fd是文件描述符,this.pos表示读取文件的位置this.[kFs]就是 fs 模块对象,调用 fs.read 方法实现选择性读取文件数据块。
通过分析可知,_read方法其实就是一个少量多次读取文件的实现方式。
前面分析了 fs.createReadStream 的实现过程,可以看出它就是对于 Stream 的一个继承实现。
而核心方法 ReadStream.prototype._read 就是实现了一个少量多次读取文件数据的方法实现。
既然如此,我们也可以实现自己的 createReadStream。
1 | // MyReadStream.js |
MyReadStream 类的调用
1 | const http = require('http') |
上面的例子 MyReadStream 类其实就是继承了 Stream.Readable类,然后实现了自己的 _read()方法。
而 _read 方法的实现就是调用了fs.read()方法逐步读取文件内容,当文件读取完成之后 this.push(null)结束。
相信看了如上例子你已经对流的使用有了基本认识,对于 fs.createReadStream 有了很直观的了解了。
九、总结
流是一种抽象,流式处理是一种思想,一种渐进式处理数据的方式。
为什么要有 Stream?
在计算机处理任务的过程中,通常会把数据加载到内存中,但是内存空间是有限的。
当数据量过大时,不可能把所有数据都放在内存里,此时就需要一种能够持续处理数据的方式,流式处理就是其中一个。
另一个重要的原因是内存的 IO 速度高于 HD 和网络的 IO 速度,又不能让内存一直处于 pending 状态。
所以需要缓冲区,而流处理恰好能够提供这样一个缓冲区。
流的优点?
1 | 节约内存 :无需先在内存中加载大量数据,然后再进行处理 |
流的特点?
1.事件: 所有流都是 EventEmitter 的实例,所以不同的流也具有不同的事件,事件也就是告知外界自己自身的工作状态的方式。
2.独立缓冲区: 可读流和可写流都有自己的独立于 V8 堆内存之外的独立缓冲区。
3.字符编码: 我们通常在进行文件读写时,操作的其实是字节流,所以在设置流参数 options 时需要注意编码格式,格式不同 chunk 的内容和大小就会不同。可读流与可写流默认的编码格式不同。
流的应用场景?
文件系统、网络系统、加密解密、压缩解压模块中都使用了流,并且都根据自身系统的需要扩展了 Stream 模块的抽象类。
附录 - 名词简介
比特流(bitstream或bit stream) 是一个比特的序列。一个字节流则是一个字节的序列,一般来说一个字节是8个比特。也可以被视为是一种特殊的比特流。
字节流(英语:byte stream) 在计算机科学中是一种比特流,不过里面的比特被打包成一个个我们叫做字节(Bytes)的单位。
流媒体(英语:Streaming media) 是指将一连串的多媒体资料压缩后,经过互联网分段发送资料,在互联网上即时传输影音以供观赏的一种技术与过程,此技术使得资料数据包得以像流水一样发送,如果不使用此技术,就必须在使用前下载整个媒体文件。
Buffer (常被翻译为缓冲区)在 Node.js 中,Buffer 类是随 Node 内核一起发布的核心库。Buffer 库为 Node.js 带来了一种存储原始数据的方法,可以让 Node.js 处理二进制数据,每当需要在 Node.js 中处理I/O操作中移动的数据时,就有可能使用 Buffer 库。原始数据存储在 Buffer 类的实例中。一个 Buffer 类似于一个整数数组,但它对应于 V8 堆内存之外的一块原始内存。任何数据的读写都会产生缓冲区。